
Introduction
Your network went down for four hours last Tuesday. Customers couldn't complete transactions. Staff scrambled without clear direction. You finally got systems back online, breathed a collective sigh of relief, and moved on.
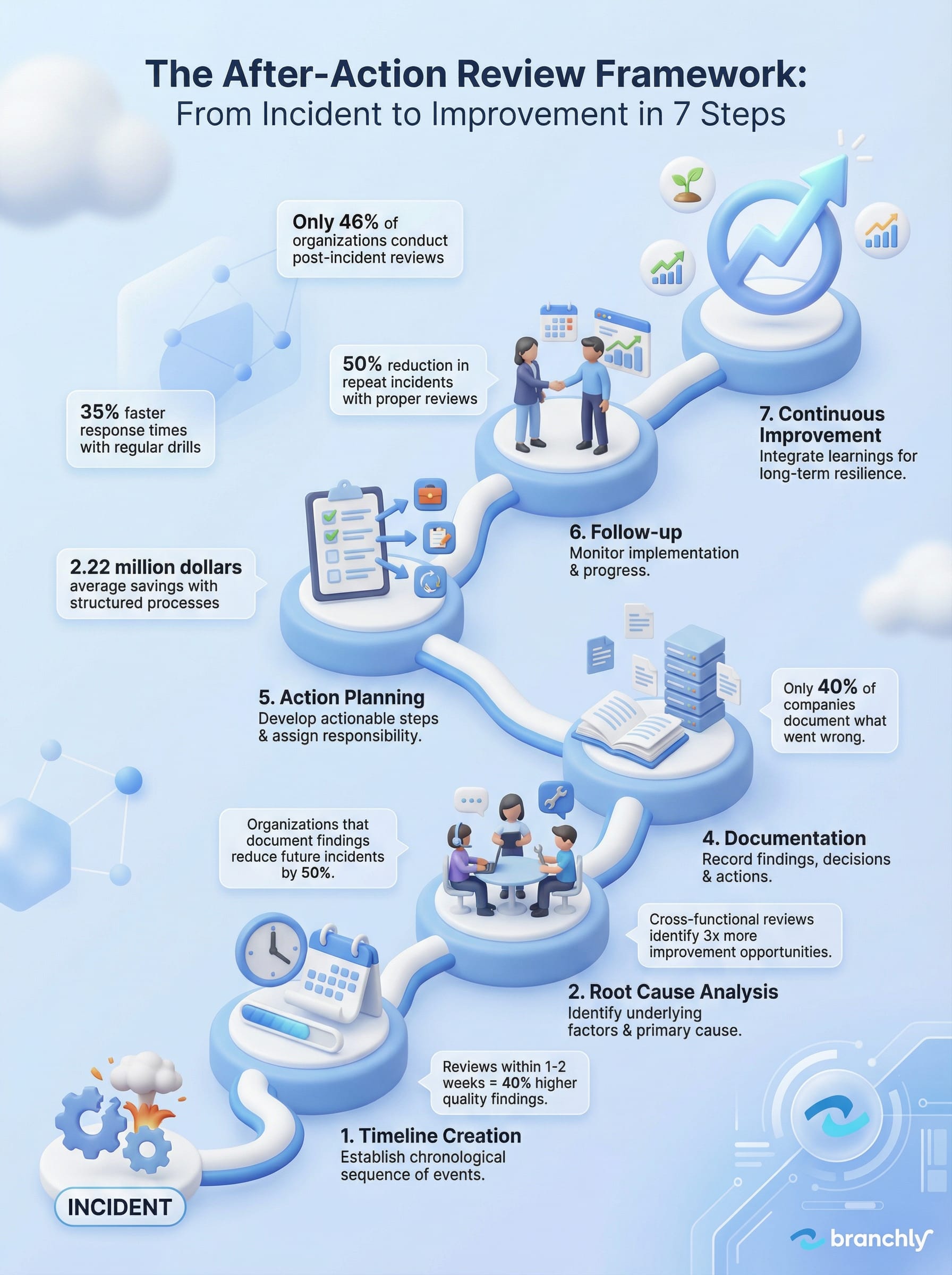
That's the problem. Less than half of organizations conduct formal after-action reviews following incidents, according to the BCI Crisis Management Report 2024. Even among those that do, most treat them as box-checking exercises rather than genuine learning opportunities. The result? The same failures happen again, costing organizations an average of $2.22 million per incident when they lack structured response processes.
The Real Cost of Skipping Post-Incident Analysis
Organizations that conduct regular incident response drills respond 35% faster to real crises. But practicing without learning from actual incidents is like running fire drills without ever checking if the extinguishers work.
The data tells a clear story. Organizations that document post-incident findings and implement changes based on those lessons reduce future incident rates by 50%. Yet only 40% of companies bother to document what went wrong. The gap between knowing you should learn from failures and actually doing it explains why the same problems keep recurring.
The financial impact is measurable. Companies using automated incident response playbooks save an average of $2.22 million per breach compared to those relying on ad-hoc responses. That difference largely reflects the accumulated wisdom of past incidents, captured and built into repeatable processes.
Quick Win
Schedule your after-action review within 48 hours of incident resolution while details are fresh. Waiting longer than two weeks dramatically reduces accuracy and participant engagement.
Why Most After-Action Reviews Fail
Walk into most post-incident meetings and you'll see the same dysfunction. Someone opens a blank document and asks, "So, what happened?" The conversation drifts. The loudest voices dominate. People defend their decisions rather than examining them. After an hour, you've got a page of vague notes that nobody will read again.
The problem isn't lack of intent. It's lack of structure. Without a consistent framework, reviews become storytelling sessions instead of analytical processes. Three common failures kill most after-action efforts before they start.
First, blame culture shuts down honest conversation. When people fear consequences for admitting mistakes, they hide problems instead of exposing them. The review captures what people are willing to say, not what actually happened.
Second, incomplete participation means missing critical perspectives. IT knows why systems failed. Operations knows how customers reacted. Compliance knows which procedures weren't followed. Leave any group out and you're analyzing partial data.
Third, no follow-through renders the entire exercise pointless. You identify five improvements, assign them to owners, and six months later nothing has changed. Without accountability mechanisms, recommendations die in someone's inbox.
The Timeline That Matters
Conduct reviews 1-2 weeks post-incident. Organizations that wait longer see 40% lower quality findings due to fading memories and reconstructed narratives.
Building a Timeline That Reveals the Truth
Every effective after-action review starts with a detailed timeline. Not a summary. Not a narrative. A minute-by-minute reconstruction of what happened, when it happened, and who did what.
Start with detection: when did the first alert fire? When did the first human notice something wrong? The gap between those two timestamps tells you whether your monitoring works. Then track the escalation: who was notified, how long until they responded, when did leadership get involved?
Map every remediation attempt. What did the team try first? When did they realize it wasn't working? What did they try next? Failed attempts matter as much as successful ones because they show where your playbooks sent people down wrong paths.
Don't forget communication milestones. When did you notify customers? When did you update staff? When did you contact regulators? These timestamps reveal whether your communication plan worked or whether people were improvising under pressure.
The timeline exposes patterns you won't see otherwise. Maybe every decision required three approval levels, adding 45 minutes to each step. Maybe the person with critical knowledge was unreachable for two hours. Maybe you had the right plan but nobody could find it.
Getting to Root Causes Instead of Symptoms
Your server crashed. That's what happened. Why did it crash? Old hardware. Why was the hardware old? Budget constraints. Why didn't you prioritize the budget? Competing initiatives. Why did those initiatives take priority? Lack of visibility into infrastructure risk.
That's root cause analysis. Keep asking why until you hit something structural rather than circumstantial. The Five Whys technique works because it forces you past easy answers to uncomfortable truths.
Most organizations stop at the first or second why. The server crashed because hardware failed. Fix: replace the server. Done. But that misses the point. You haven't addressed why critical infrastructure reached end-of-life without replacement, which means it will happen again somewhere else.
Fishbone diagrams offer another approach. Draw the problem at the head. Then branch out to categories: people, process, technology, environment. Under each branch, list contributing factors. The visual format helps teams see how multiple small failures combined to create one large incident.
Watch Your Language
Replace 'who caused this?' with 'what conditions allowed this?' The first question prompts defensiveness. The second prompts analysis.
Who Needs to Be in the Room
The after-action review isn't just for the incident response team. You need everyone who touched the incident, everyone who felt its impact, and everyone who will implement changes based on what you learn.
Start with your responders: IT, operations, security, facilities, whoever fought the fire. They know what worked and what didn't at a tactical level.
Pull in your stakeholder representatives. Customer service can explain how customers reacted. HR can describe employee concerns. Finance can quantify the cost. These perspectives prevent technical tunnel vision.
Include legal and compliance, especially in regulated industries. They can identify documentation gaps, regulatory implications, and liability exposures you might miss.
And bring leadership. Not to judge, but to understand. Executives who sit through after-action reviews make better budget decisions, policy decisions, and strategic decisions. They've seen firsthand what breaks under pressure.
Cross-Functional = Complete Picture
Reviews with only IT participation miss 60% of operational and business impacts. Organizations with full cross-functional reviews identify 3x more improvement opportunities.
Turning Findings Into Action That Actually Happens
You've identified twelve problems. Great. Now what? Without a clear path from finding to fix, your review becomes another report that gathers dust.
First, prioritize ruthlessly. Not every finding needs immediate action. Sort them by potential impact and likelihood of recurrence. A high-impact, high-probability problem gets fixed now. A low-impact, one-time fluke gets documented and monitored.
Second, assign specific owners with specific deadlines. "IT will improve monitoring" accomplishes nothing. "Sarah will implement automated alerting for database connection failures by March 15" creates accountability.
Third, build follow-up into your calendar. Schedule a 30-day check-in to review progress. Schedule a 90-day audit to verify completion. High-performing security teams conduct these follow-ups religiously, which explains why they see 50% fewer repeat incidents.
Fourth, update your playbooks immediately. If your response plan said to do X but the team actually needed to do Y, change the plan now while the details are clear. Waiting until the next crisis means repeating the same mistakes.

The After-Action Review Framework
From Incident to Improvement in 7 Steps
What to Measure to Know If You're Improving
You can't manage what you don't measure. After-action reviews should generate both qualitative insights and quantitative metrics.
Track your detection time: how long from incident start to human awareness? Organizations with effective monitoring detect incidents 35% faster than those relying on customer reports.
Measure your response time: how long from detection to first action? From first action to resolution? These numbers tell you whether your team knows what to do and has the tools to do it.
Count your communication touchpoints: how many updates did you send? How quickly? Did you hit all stakeholder groups? Communication breakdowns extend incidents and damage trust.
Calculate your financial impact: direct costs, opportunity costs, reputation costs. The number matters less than the trend. Are incidents getting more or less expensive over time as you implement improvements?
But don't ignore qualitative data. How did the team feel during response? Were roles clear? Did anyone feel unsupported? Psychological and organizational factors often predict future performance better than technical metrics.
Template Time-Saver
Create a standard after-action review template covering timeline, root causes, impacts, findings, and action items. Consistent structure ensures nothing gets missed and makes trends visible across multiple incidents.
The Documentation Nobody Wants to Do But Everyone Needs
Only 40% of organizations document their post-incident findings. That statistic represents millions of dollars in repeated mistakes and preventable failures.
Documentation serves multiple purposes. It creates institutional memory so knowledge survives staff turnover. It provides evidence of due diligence for regulators and auditors. It enables trend analysis across incidents. It protects you legally by showing you took reasonable steps to prevent recurrence.
Your after-action report should include background and scope, detailed timeline, root cause analysis, impact assessment (operational, financial, reputational), findings organized by category, prioritized recommendations, action plan with owners and deadlines, and lessons learned for future incidents.
Store documentation where people can find it. The best after-action report is worthless if nobody remembers it exists six months later when a similar incident occurs.
For regulated industries, documentation isn't optional. NCUA, FFIEC, and FINRA all expect evidence that you analyze incidents and implement improvements. Incomplete documentation during an audit can trigger fines regardless of how well you actually responded.
Making Reviews Psychologically Safe
The most valuable insights come from people admitting what they did wrong. That only happens if they trust they won't be punished for honesty.
Set the ground rule explicitly at the start of every review: this is about fixing systems, not punishing people. Individual mistakes usually reflect inadequate training, unclear procedures, missing tools, or competing priorities. Those are organizational problems.
Model the behavior you want. If you're leading the review, acknowledge your own mistakes first. "I should have escalated this sooner" or "I didn't realize that dependency existed" shows that admitting gaps is acceptable and expected.
Watch your language. "Why didn't you call the backup contact?" sounds accusatory. "What prevented you from calling the backup contact?" invites explanation. The second version assumes barriers rather than negligence.
If someone made a genuinely reckless decision, handle it separately and privately. Mixing performance management with after-action reviews poisons the process for everyone.
Blameless Doesn't Mean Consequenceless
Blameless culture addresses systemic failures, not individual accountability. But handle performance issues privately, never during the review itself.
When to Bring in Outside Help
Most after-action reviews can and should be handled internally. But some situations benefit from external facilitation.
Consider outside help for high-stakes incidents with regulatory implications, major financial losses, or significant reputational damage. An external reviewer brings credibility and objectivity that protects you during audits.
Bring in a facilitator when internal politics threaten honest conversation. If the incident exposed departmental conflicts or leadership failures, an outside party can navigate those dynamics more effectively than internal staff.
Get external expertise when the incident involves technical complexity beyond your team's knowledge. If a supply chain attack compromised your systems, you probably need specialized help understanding what happened and how to prevent recurrence.
But don't outsource the process entirely. External reviewers should supplement internal knowledge, not replace it. Your team understands your environment, culture, and constraints better than any consultant.
Building a Culture That Learns From Failure
The after-action review is a tool. But tools don't create change by themselves. You need an organizational culture that values learning more than blame, improvement more than perfection.
That culture starts at the top. When leadership treats incidents as learning opportunities rather than failures, everyone else follows. When executives sit through after-action reviews and ask curious questions rather than accusatory ones, teams open up.
Make reviews routine. Don't just review disasters. Review near-misses, successful responses, and periodic drills. The more normal the process becomes, the less threatening it feels.
Share findings broadly. When one department learns from an incident, help other departments learn too. Maybe branch operations experienced a power outage. IT needs to know what worked and what didn't so they can prepare the entire network.
Celebrate improvements, not just resolutions. When you implement a recommendation from an after-action review and it prevents a future incident, recognize that publicly. It reinforces that the review process has real value.
Review Your Reviews
Quarterly, look back at your after-action reviews. Are recommendations getting implemented? Are similar incidents decreasing? Are reviews getting more efficient? Your review process needs continuous improvement too.
Summary
After-action reviews transform incidents from costly disruptions into valuable learning opportunities, but only when conducted with structure, psychological safety, and genuine commitment to change. Organizations that master this process reduce repeat incidents by 50%, respond 35% faster to new crises, and save an average of $2.22 million per incident. The framework is straightforward: conduct reviews within one to two weeks while details are fresh, build complete timelines with precise timestamps, dig past symptoms to root causes using techniques like the Five Whys, include cross-functional participants from response teams to leadership, document findings in standardized templates, convert insights into action plans with specific owners and deadlines, and follow up religiously to ensure improvements actually happen. What separates successful reviews from box-checking exercises is culture. Teams that treat reviews as learning opportunities rather than blame sessions surface honest insights. Organizations that implement recommendations and track their effectiveness build genuine resilience. The goal isn't to prevent all incidents, which is impossible, but to ensure you never fail the same way twice.
Key Things to Remember
- ✓Conduct after-action reviews within 1-2 weeks post-incident when details are fresh and participant memory is accurate
- ✓Build detailed timelines with precise timestamps to expose patterns, delays, and decision bottlenecks invisible in narrative summaries
- ✓Use root cause analysis techniques like the Five Whys to identify structural problems instead of stopping at surface symptoms
- ✓Include cross-functional participants from IT, operations, legal, compliance, and leadership for complete operational and business context
- ✓Convert findings into action plans with specific owners, deadlines, and follow-up mechanisms to ensure recommendations get implemented
How Branchly Can Help
Branchly automatically captures the detailed timeline, decision points, and action logs you need for effective after-action reviews. During incidents, our platform timestamps every task, approval, communication, and status change, creating a complete audit trail without manual documentation. After resolution, our Intelligence Layer analyzes response data to identify bottlenecks, skipped steps, and delays, surfacing insights that would take hours to compile manually. You get standardized after-action reports with root cause analysis suggestions, participant feedback collection, and built-in action tracking to ensure recommendations actually get implemented. The system even compares incidents across locations to identify patterns and prevent similar failures organization-wide.
Citations & References
- [1]How to Conduct a Crisis Post-Incident Review and Improve Business Resilience — CrisisCompass com.au View source ↗
- [2]
- [3]
- [4]Post-incident review best practices | Jira Service Management Cloud | Atlassian Support atlassian.com View source ↗
- [5]
- [6]
- [7]Crisis Management: Executive Guide to Workplace Disruption Response and Recovery - R3 Continuum r3c.com View source ↗
- [8]Post Incident Analysis (PIA) - A Method to Analyze Your Actions During a BCP Event mha-it.com View source ↗