
Introduction
Your payment system goes offline at 2 PM on a Friday. The branch manager calls IT. IT says they need approval from the VP of Operations. The VP is in meetings. Forty-five minutes pass before anyone with decision authority even knows there's a problem.
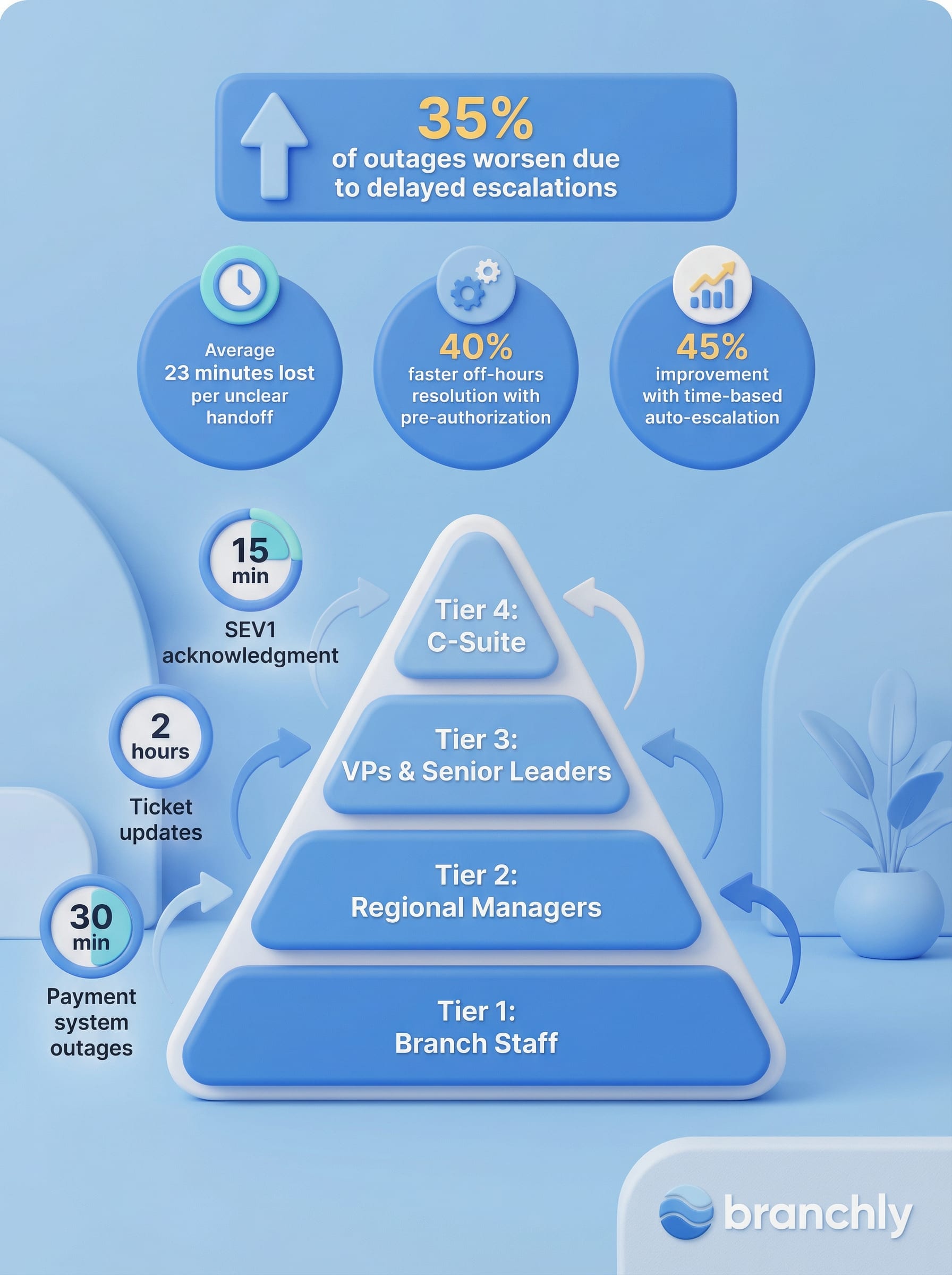
This isn't a hypothetical scenario. According to incident response data, 35% of outages get worse because of delayed escalations. The root cause? Organizations operate with vague criteria like 'escalate when necessary' or 'contact your supervisor if it seems serious.' When seconds matter, ambiguity kills response time.
A functioning escalation framework answers three questions before any crisis hits: What triggers escalation? Who has authority to decide? How do we prevent approvals from becoming bottlenecks? This guide breaks down how to build those answers into your response plans.
Why Escalation Frameworks Fail
Most escalation problems stem from a single flaw: they're designed during calm moments by people who've never actually used them under pressure. The result is a hierarchical approval chain that looks logical on paper but collapses the moment someone isn't available.
Three patterns repeat across failed escalations. First, unclear ownership. When roles overlap or responsibilities aren't explicit, incidents bounce between teams. Context gets lost. Customers repeat their issues multiple times. One financial services company tracked this pattern and found that unclear handoffs added an average of 23 minutes to every escalated incident.
Second, approval bottlenecks. If your engineer can't restart a critical system without waking up a VP at 3 AM, you've built delay into your response. After one organization replaced blanket approval requirements with pre-authorized actions based on severity, their off-hours resolution time dropped 40%.
Third, vague triggers. 'Escalate if needed' or 'contact management for serious issues' force frontline staff to make judgment calls they're not equipped to make. They either escalate everything, flooding leadership with minor issues, or hesitate too long on genuine emergencies.
Test Your Escalation Triggers
Pull five recent incidents and walk through your escalation criteria. If different people would make different decisions about when to escalate, your triggers are too vague. Rewrite them with specific metrics: time thresholds, user counts, revenue impact, or regulatory implications.
Building a Tiered Escalation Structure
Effective escalation structures use tiers that match both expertise and decision authority. Most organizations need four levels, though your structure should reflect your actual org chart and complexity.
Tier 1 handles initial response. Branch staff, frontline managers, or first responders deal with incidents within their scope and authority. They have clear playbooks for common scenarios: power outages, minor system glitches, customer complaints. They escalate when the issue exceeds their documented authority, when resolution time passes a specific threshold, or when the incident meets predefined severity criteria.
Tier 2 coordinates multi-location or technical issues. Regional managers, IT supervisors, or operations leads step in when incidents affect multiple sites, require technical expertise beyond frontline capability, or involve vendor coordination. They have authority to redirect resources, activate backup systems, or approve overtime without seeking higher approval.
Tier 3 manages enterprise-wide crises. VPs, compliance officers, and senior operations leaders handle incidents with significant business impact, regulatory implications, or reputational risk. They make decisions about public statements, regulatory notifications, and resource allocation across the organization.
Tier 4 involves executive leadership. C-suite and board members engage only when the incident threatens organizational viability, requires major capital decisions, or demands board-level governance. This tier should rarely activate. If your CEO is involved in routine incidents, your lower tiers aren't working.
Dual Escalation Paths
Build separate technical and managerial escalation paths. Technical escalation follows expertise: specialist, senior engineer, architect. Managerial escalation follows business authority: supervisor, director, VP. Some incidents need one path, some need both, but they shouldn't be the same chain.
Defining Specific Escalation Triggers
Triggers need numbers. Time thresholds, user counts, financial impact, and regulatory requirements all provide concrete decision points that remove guesswork.
Time-based triggers establish clear deadlines. A severity-1 incident unacknowledged after 15 minutes automatically escalates. An open ticket with no update in 2 hours moves up the chain. These thresholds prevent incidents from sitting in queues because someone assumed someone else was handling it.
Impact-based triggers tie escalation to business consequences. Payment systems down for more than 30 minutes? Escalate to Tier 3. More than 1,000 users affected? Immediate escalation. Customer-facing systems offline during peak hours? Different threshold than overnight outages. This recognizes that a minor technical issue with major business impact needs faster escalation than a complex technical problem with limited customer exposure.
Compliance and safety triggers bypass normal escalation entirely. Anything involving regulatory reporting requirements, data breaches, customer safety, or legal liability goes directly to the appropriate authority level regardless of other factors. A potential FDIC reporting issue doesn't wait in queue behind a printer malfunction.
Authority boundaries prevent unnecessary escalation. If Tier 2 can authorize up to $5,000 in emergency vendor expenses, routine repairs don't need VP approval. If regional managers can approve location closures for safety reasons, they don't need to track down executives during a severe weather event.

Sample Escalation Trigger Matrix
Time, impact, and compliance criteria for each tier
Communication Protocols During Escalation
How you communicate during escalation matters as much as who you contact. Dedicated channels for urgent incidents prevent critical messages from getting lost in normal communication noise.
High-severity incidents should trigger specific communication methods. Phone calls, not emails. Dedicated Slack channels, not general threads. Text messages to backup contacts if primary doesn't respond within defined windows. One credit union implemented a simple rule: SEV1 incidents require voice confirmation that the next tier received the escalation. Email alone wasn't sufficient. This eliminated the 'I didn't see the message' problem that previously added 20-30 minutes to their response times.
Context transfer is where most escalations break down. The person receiving the escalation needs specific information: what happened, what's been tried, what's currently impacted, and what specific decision or resource is needed. Standardized escalation templates eliminate the phone-tag problem where responders have to track down basic information before they can actually help.
Status updates should flow both up and down. The person who escalated the incident shouldn't be left wondering what's happening. Set expectations: 'You'll get an update every 15 minutes' or 'We'll notify you when resolution is in progress.' This prevents duplicate escalations where the same incident gets elevated multiple times because nobody knows it's already being handled.
Document Backup Contacts
Every tier should have at least two named contacts with clear 'if primary doesn't respond within X minutes, contact secondary' instructions. Include multiple contact methods: mobile, desk phone, personal cell if they've agreed to it. Test these quarterly because people change roles.
Preventing Escalation Bottlenecks
The best escalation frameworks include built-in mechanisms to prevent single points of failure. Pre-approved actions, time-based automatic escalation, and clear authority boundaries all reduce dependency on specific individuals.
Pre-authorization matrices define what actions each tier can take without seeking approval. Your Tier 1 staff might be pre-authorized to close a location for safety reasons, activate backup power systems, or spend up to $500 on emergency supplies. These authorities should be documented, trained on, and reviewed annually. When staff know what they can do without asking, response accelerates.
Automatic escalation prevents incidents from stalling. If a Tier 2 responder doesn't acknowledge an escalation within 15 minutes, the system automatically notifies Tier 3. This doesn't mean Tier 2 failed. It means the incident is serious enough that it shouldn't wait for someone to return from lunch or finish a meeting.
Parallel notification for critical scenarios can bypass sequential escalation. A data breach doesn't go from IT tech to IT supervisor to IT director to CISO over 45 minutes. It notifies the CISO, compliance officer, and legal counsel simultaneously. Yes, this might over-notify for false alarms. That's acceptable. The cost of delayed notification on genuine breaches far exceeds the cost of occasionally pulling senior leaders into non-issues.
Real Data: The Cost of Delays
Organizations with time-based auto-escalation reduced average resolution time by 45%. Those with pre-defined authority levels cut off-hours response time by 40%. Source: Incident management benchmark data from enterprise IT operations.
Using RACI to Clarify Escalation Roles
RACI matrices (Responsible, Accountable, Consulted, Informed) eliminate the role confusion that slows escalations. For every incident type and severity level, the matrix answers who does the work, who owns the decision, who provides input, and who needs updates.
Responsible means doing the actual response work. For a payment system outage, IT staff are responsible for diagnostics and repairs. Branch managers are responsible for communicating with customers. These people take action.
Accountable means owning the outcome. Only one person should be accountable for each incident or decision point. For that payment outage, the IT Director might be accountable for technical resolution while the Operations VP is accountable for business continuity decisions. If something goes wrong, there's no question who owns it.
Consulted means providing expertise before decisions are made. Compliance might be consulted before sending customer communications. Legal might be consulted before making public statements. These stakeholders have input but don't own the decision.
Informed means receiving updates but not participating in decisions. Executive leadership might be informed about all SEV1 incidents without being involved in tactical response. The board gets informed about major crises after initial response is underway.
Build your RACI by incident type and severity level. A minor facility issue has a different RACI than a cybersecurity incident. Review these matrices with your teams so everyone knows their role before incidents happen.
Testing and Refining Your Escalation Framework
Escalation frameworks fail in practice because they're never tested under realistic conditions. Running tabletop exercises that specifically stress-test escalation paths reveals gaps that look invisible on paper.
Design exercises around common failure modes. Run a scenario where the primary contact is unavailable. Does the framework still work? Test an incident that starts small but rapidly escalates. Do your triggers catch it fast enough? Try an off-hours scenario when senior leadership isn't immediately reachable. Can your team make the necessary decisions?
Measure what matters during exercises. Track time from incident start to escalation. Measure time from escalation to acknowledgment. Count how many times context had to be re-explained. Note any decisions that got delayed because authority wasn't clear. These metrics tell you where your framework has friction.
Review actual escalations quarterly. Pull data on real incidents: Did escalation happen when it should have? Was it delayed? Did issues get escalated too early or too late? Every real incident is free data about whether your framework matches operational reality.
Update your framework based on what you learn. If you find that certain incident types consistently require Tier 3 involvement, adjust your triggers so they escalate faster. If pre-authorization thresholds are too low and creating unnecessary escalations, raise them. Your framework should evolve.
Post-Incident Questions
After every escalation, ask: Did the right person get involved at the right time? Did they have the information they needed? Was authority to act clear? Would we handle it differently next time? If yes to that last question, update your framework immediately.
Common Escalation Mistakes to Avoid
Some escalation patterns sound reasonable but consistently cause problems in practice. Recognizing these patterns helps you design around them.
Escalating by committee creates delays. If three people need to agree before escalation happens, you've built consensus into time-critical decisions. Designate a single decision-maker for escalation calls. Others can provide input, but one person makes the call.
Escalating everything because triggers are too sensitive wastes leadership bandwidth and creates alert fatigue. If your VP gets notified 30 times a month, they'll start ignoring escalations. Calibrate your thresholds so escalations are meaningful but not rare. Most organizations find that 3-5 genuine escalations per month to senior leadership represents the right balance.
Never escalating because triggers are too strict is equally problematic. If frontline staff feel they'll get in trouble for escalating, they'll wait too long. Make it clear that appropriate escalation is expected behavior, not a failure. Track and celebrate cases where early escalation prevented bigger problems.
Forgetting about de-escalation causes resource waste. Build clear criteria for when incidents move back down the chain. Once a payment system is restored and monitoring confirms stability, Tier 3 doesn't need to stay engaged. Document when and how to de-escalate so senior leaders can return to strategic work.
The Hidden Cost of Poor Escalation
Beyond longer outages, poor escalation erodes trust. Staff lose confidence in leadership responsiveness. Customers see disorganized response. Regulators question your operational controls. One well-designed escalation framework prevents all three problems.
Summary
Escalation frameworks work when they answer three questions before incidents occur: what triggers escalation, who has authority to act, and how to prevent approval bottlenecks from extending response time. Build specific, measurable triggers based on time, impact, and compliance requirements. Define clear tiers with explicit authorities so responders know what they can do without seeking permission. Use RACI matrices to eliminate role confusion. Test your framework quarterly with realistic scenarios that stress-test common failure modes. Most importantly, review every real escalation to identify gaps between your documented process and operational reality. The goal isn't perfection. It's ensuring that when your payment system crashes or your building loses power, everyone knows exactly who needs to know, who can decide what, and how fast those decisions happen.
Key Things to Remember
- ✓35% of outages worsen due to delayed escalations caused by unclear triggers and undefined decision authority
- ✓Effective escalation uses four tiers with specific triggers based on time thresholds, business impact, and compliance requirements
- ✓Pre-authorization matrices and time-based auto-escalation prevent single points of failure and approval bottlenecks
- ✓RACI matrices eliminate role confusion by clearly defining who is Responsible, Accountable, Consulted, and Informed for each incident type
- ✓Regular testing and post-incident reviews ensure escalation frameworks match operational reality and evolve with organizational needs
How Branchly Can Help
Branchly automates escalation decisions based on your predefined triggers and authority structure. The platform monitors incident severity, elapsed time, and business impact in real-time, automatically notifying the appropriate tier when thresholds are met. Pre-built RACI templates map to your org chart, and the Command Center provides live visibility into who's been notified, who's acknowledged, and where bottlenecks exist. Every escalation is logged with timestamps and context, creating defensible audit trails while ensuring that critical decisions happen at the right level without manual coordination delays.
Citations & References
- [1]
- [2]
- [3]
- [4]
- [5]What is Escalation Path? Complete Guide to Issue Resolution, Support Hierarchy & Crisis Management Workflows | PostNext postnext.io View source ↗
- [6]
- [7]Comprehensive Guide to Crisis Management: Strategies for Success USA protechtgroup.com View source ↗
- [8]Proven escalation policy framework (w/ templates & checklists) | Hyperping Blog hyperping.com View source ↗
- [9]
- [10]
- [11]
- [12]
- [13]